HDFS
HDFS HA
HDFS NameNode 和 YARN ResourceManger 的高可用方案类似,HDFS NameNode 对于数据存储和数据一致性的要求比 YARN ResourceManger 高得多,所以 HDFS NameNode 的高可用实现更为复杂一些。
NameNode 高可用整体架构
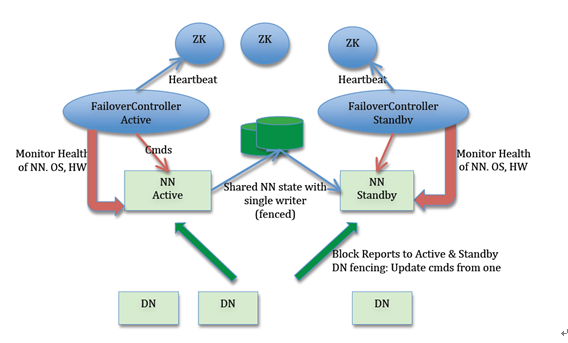
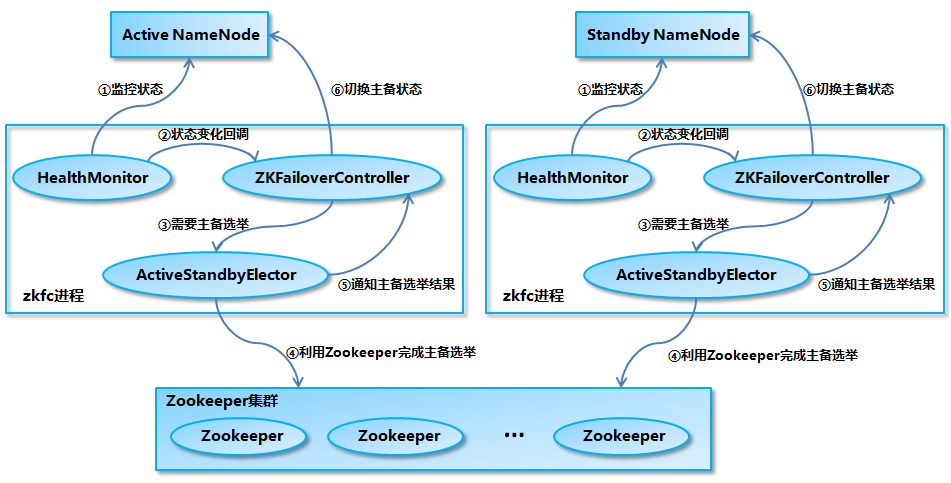
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现.
主备切换流程
写入过程
Hive 特点
HQL, MapReduce 参考
Yarn
Yarn 二次调度
Yarn 采用 Master/Slave 结构,整体采用双层调度架构。
- 在第一层的调度是 ResourceManager 和 NodeManager: ResourceManager 是 Master 节点,相当于 JobTracker,包含 Scheduler 和App Manager 两个组件,分管资源调度和应用管理;NodeManager 是 Slave 节点,可以部署在独立的机器上,用于管理机器上的资源。NodeManager 会向 ResourceManager 报告它的资源数量、使用情况,并接受 ResourceManager 的资源调度。
- 第二层的调度指的是 NodeManager 和 Container。NodeManager 会将 Cpu&内存等资源抽象成一个个的 Container,并管理它们的生命周期。
通过采用双层调度结构将 Scheduler 管理的资源由细粒度的 Cpu&内存变成了粗粒度的 Container,降低了负载。在 App Manager 组件中也只需要管理 App Master,不需要管理任务调度执行的完整信息,同样降低了负载。通过降低 ResourceManager 的负载,变相地提高了集群的扩展性。
资源调度和任务调度的流程
- 粗粒度资源申请(Spark): 在Application执行之前,将所有的资源申请完毕,当资源申请成功后,才会进行任务的调度,当所有的task执行完成后,才会释放这部分资源。
- 细粒度资源申请(MapReduce): Application执行之前不需要先去申请资源,而是直接执行,让job中的每一个task在执行前自己去申请资源,task执行完成就释放资源。
Spark
Basic
- RDD(Resilient,Distributed,Dataset) 不可变的分布式对象集合
-
DAG 有向无环图: 描述了RDD的依赖关系,这种关系也被称之为lineage,RDD的依赖关系使用Dependency维护。
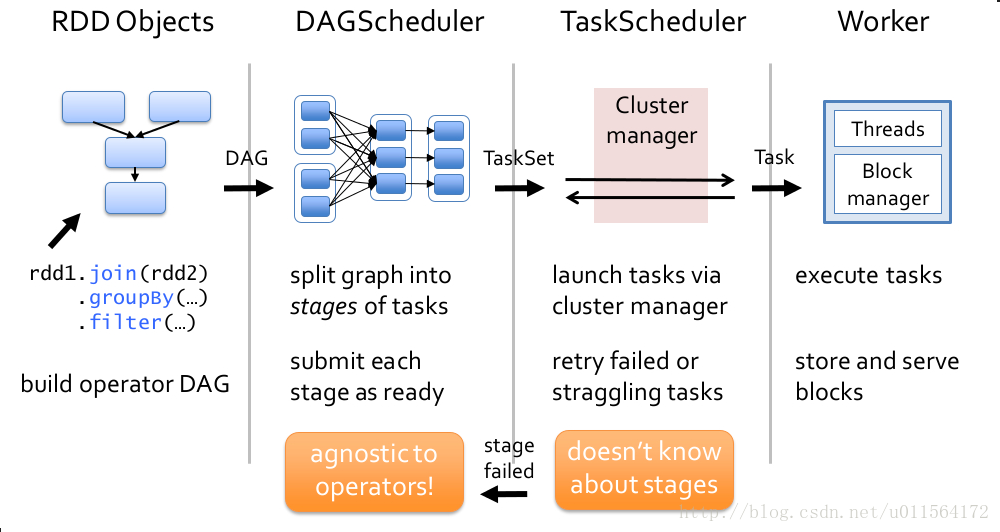
- 宽依赖、窄依赖,DAGScheduler根据 wide dependency划分Stage
- RDDs 算子: Transformations and Actions, Spark is lazy
- Transformations:
- Narrow Transformation: map, union, flatmap, filter…
- Wide Transformation: join, reduceByKey, groupByKey, sortByKey…
- Action: reduce, count, countByKey, collect, first, take, foreach, OutputFunction like saveAsTextFile…
Job:提交给spark的任务。 Stage:每一个job处理过程要分为的几个阶段。(根据宽依赖划分)
1
2
3
stage里的task的数量由输入文件的切片个数来决定的。
在HDFS中不大于128m的文件算一个切片(默认128m)。
通过算子修改了某一个rdd的分区数量,task数量也会同步修改。
Task:是每一个job处理过程要分几为几次任务。Task是任务运行的最小单位。最终是要以task为单位运行在executor中。
1
关系:Job <---> 一个或多个stage <---> 一个或多个task
并行度:
- 理论上:每一个stage下有多少的分区,就有多少的task,task的数量就是我们任务的最大的并行度。
- 实际上:最大的并行度,取决于我们的application任务运行时使用的executor拥有的cores的数量。
container 节点:可以起一个或多个Executor。
Executor:由若干虚拟的core组成,每个Executor的每个core一次只能执行一个Task。
Partiton:Task执行的结果就是生成了目标RDD的一个partition。
与Hadoop MR相比
- 迭代效率高,Hadoop MR 中间结果都需要落地,io操作影响性能;
- 容错好,RDD可根据血缘关系找回,MR需要从头计算;
- mapreduce只提供了map和reduce两种操作,spark 还有Streaming、GraphX;
- spark框架生态更复杂。
运行流程
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
spark on yarn cluster 与 client 模式的区别
区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。 而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。
RDD,Dataset,Dataframe
RDD
弹性分布式数据集 Resilient Distributed Dataset 是分布式的Java对象的集合。
- 优点:
- 强大,内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据;
- 面向对象编程,直接存储的java对象,类型转化也安全;
- 缺点:
- 由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦;
- 默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁;
DataFrame
DataFrame是分布式的Row对象的集合。
- 优点:
- 结构化数据处理非常方便,支持Avro, CSV, Elastic search, Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表;
- 有针对性的优化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数;
- hive兼容,支持hql,udf等;
- 缺点:
- 编译时不能类型转化安全检查,运行时才能确定是否有问题
- 对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
Dataset
- DataFrame = Dataset[Row], Dataset每一个record存储的是一个强类型值而不是一个Row。
- DataFrame和Dataset API都是基于Spark SQL引擎构建的
Spark on Yarn
并行度
RDD:spark.default.parallelism
Spark SQL: spark.sql.shuffle.partitions=[num_tasks]
RDD.repartition:给RDD重新设置partition的数量 [repartitions 或者 coalesce]
Spark Shuffle
Shuffle阶段是指从Map的输出开始,包括系统执行排序以及传送Map输出到Reduce作为输入的过程。
Sort阶段是指对Map端输出的Key进行排序的过程。不同的Map可能输出相同的Key,相同的Key必须发送到同一个Reduce端处理。
Shuffle阶段可以分为Map端的Shuffle和Reduce端的Shuffle。
Map 端Shuffle: 分区partition => 写入环形缓冲区 => 执行溢出写 => 归并merge
Reduce 端Shuffle: 复制copy => 归并merge => reduce
Shuffle是连接map阶段和reduce阶段的桥梁。(宽依赖涉及shuffle操作)
shuffle操作需要将数据进行重新聚合和划分,然后分配到集群的各个节点上进行下一个stage操作,这里会涉及集群不同节点间的大量数据交换。由于不同节点间的数据通过网络进行传输时需要先将数据写入磁盘,因此集群中每个节点均有大量的文件读写操作,从而导致shuffle操作十分耗时。
以reduceByKey 为例:
- Shuffle Write:上一个stage的每一个map task就必须保证将自己处理的当前分区中的数据相同的key写入一个分区文件中,可能会写入多个不同的分区文件中。
- Shuffle Read:reduce task就会从上一个stage的所有task所在的机器上寻找属于自己的那些分区文件,这样就可以保证每一个key所对应的value都会汇聚在同一个节点上去处理和聚合。
spark RDD中的shuffle算子:去重distinct()、聚合reduceByKey()、排序sortByKey()、重分区repartition()等
Spark中有两种Shuffle管理类型:
HashShuffle
- 产生的磁盘小文件的个数:M(map task的个数)*R(reduce task的个数)
- 优化后: C(core的个数)*R(reduce的个数)
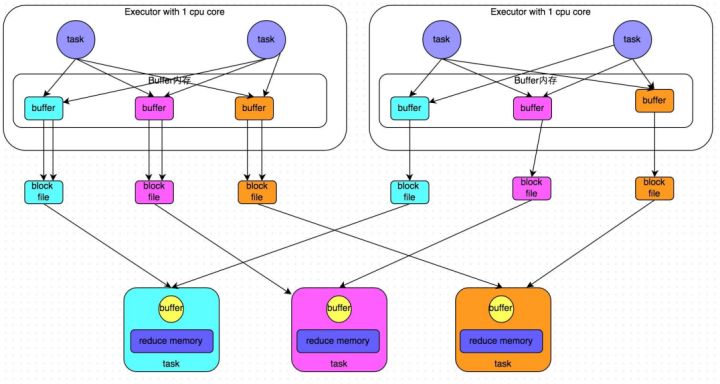
SortShuffle
- 产生的磁盘的小文件为:2*M(map task的个数)
- reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据
- bypass机制
数据倾斜
原理: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,此时如果某个key对应的数据量特别大的话,就会发生数据倾斜
定位: 通过Spark Web UI来查看当前运行的stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。知道数据倾斜发生在哪一个stage之后,接着我们就需要根据stage划分原理,推算出来发生倾斜的那个stage对应代码中的哪一部分,这部分代码中肯定会有一个shuffle类算子。通过countByKey查看各个key的分布。
解决:
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 局部聚合和全局聚合,进行两阶段聚合
- 将reduce join转为map join,不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作。
- 采样倾斜key并分拆join操作(join的两表都很大,但仅一个RDD的几个key的数据量过大)
- 对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本来,然后统计一下每个key的数量,计算出来数据量最大的是哪几个key。
- 然后将这几个key对应的数据从原来的RDD中拆分出来,形成一个单独的RDD,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个RDD。
- 接着将需要join的另一个RDD,也过滤出来那几个倾斜key对应的数据并形成一个单独的RDD,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个RDD。
- 再将附加了随机前缀的独立RDD与另一个膨胀n倍的独立RDD进行join,此时就可以将原先相同的key打散成n份,分散到多个task中去进行join了。
- 而另外两个普通的RDD就照常join即可。
- 最后将两次join的结果使用union算子合并起来即可,就是最终的join结果。
- 使用随机前缀和扩容RDD进行join(RDD中有大量的key导致数据倾斜)
参考:https://www.infoq.cn/article/the-road-of-spark-performance-tuning
Structured Streaming
基于 Spark SQL 的全新流计算引擎 Structured Streaming,让用户像编写批处理程序一样简单地编写高性能的流处理程序。
Structured Streaming 则是在 Spark 2.0 加入的经过重新设计的全新流式引擎。一个流的数据源从逻辑上来说就是一个不断增长的动态表格,随着时间的推移,新数据被持续不断地添加到表格的末尾。用户可以使用 Dataset/DataFrame 或者 SQL 来对这个动态数据源进行实时查询。
Sprak Streaming 连接Kafka
两种方式:
基于Receiver方式, 使用High API, 对于所有的接收器,从kafka接收来的数据会存储在spark的executor中。
- 在Receiver的方式中,Spark中的partition和kafka中的partition并不是相关的;
- 对于不同的Group和topic我们可以使用多个Receiver创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream;
- offset 存在zookeeper 中,由于Spark Streaming消费的数据和Zookeeper中记录的offset不同步,这种方式偶尔会造成数据重复消费;
- WAL机制可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。
Direct 方式, 使用Low API, 直接消费Kafka Partition数据。
- 其会周期性的获取Kafka中每个topic的每个partition中的最新offsets;
- 之后根据设定的maxRatePerPartition来处理每个batch;
- Kafka中的partition与RDD中的partition是一一对应的并行读取Kafka数据;
- 高效:在Receiver的方式中,为了达到0数据丢失需要将数据存入Write Ahead Log中,这样在Kafka和日志中就保存了两份数据;
- 使用Low API, Offsets 利用 Spark Streaming的checkpoints进行记录, 保证精确一次性。
实例
Spark 离线优化,存在笛卡尔积
distinct 底层实现: reduceByKey
Flink
Window
滚动、滑动、Session、Global Window。
Watermark
当Flink中的运算符接收到水印时,它明白(假设)它不会看到比该时间戳更早的消息。watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
Flink里的时间类型包括:
- Event Time:数据本身的产生时间。
- Ingestion Time:进入Flink系统的时间。
- Processing Time:被处理的时间。
Event Time是最能反映数据时间属性的,但是Event Time可能会发生延迟或乱序,Flink系统本身只能逐个处理数据,故对于Event Time可能会发生延迟或乱序情况,使用watermark机制结合window来解决。
WaterMark 的生成:
用的多的是 Periodic Watermarks:
class BoundedOutOfOrdernessGenerator extends AssignerWithPeriodicWatermarks[MyEvent] {
val maxOutOfOrderness = 3500L; // 3.5 seconds
var currentMaxTimestamp: Long;
override def extractTimestamp(element: MyEvent, previousElementTimestamp: Long): Long = {
val timestamp = element.getCreationTime()
currentMaxTimestamp = max(timestamp, currentMaxTimestamp)
timestamp;
}
override def getCurrentWatermark(): Watermark = {
// return the watermark as current highest timestamp minus the out-of-orderness bound
new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}
程序中有一个extractTimestamp方法,就是根据数据本身的Event time来获取;还有一个getCurrentWatermar方法,是用currentMaxTimestamp - maxOutOfOrderness来获取的。
所以 [0,10) 秒的数据会在15秒被watermark触发。
一般而言,Window的触发需要满足:
- Event Time < watermark时间(对于late element太多的数据而言)
或者:
- Watermark时间 >= window_end_time
- 在[window_start_time,window_end_time)中有数据存在。
处理乱序:window中可以对input进行按照Event Time排序。
在多并行度的情况下,Windows总是以小的WaterMark时间为标准。
Checkpoint机制
Spark Checkpoint:
- 在spark core中对RDD做checkpoint,可以切断做checkpoint RDD的依赖关系,将RDD数据保存到可靠存储(如HDFS)以便数据恢复;
- 在spark streaming中,使用checkpoint用来保存DStreamGraph以及相关配置信息,以便在Driver崩溃重启的时候能够接着之前进度继续进行处理。
- 核心方法是
doCheckpoint()
Spark job 的提交执行是异步的,与 checkpoint 操作并不是原子操作。这样的机制会引起数据重复消费问题。
Flink Checkpoint
checkpoint 原理就是连续绘制分布式的快照,而且非常轻量级,可以连续绘制,并且不会对性能产生太大影响。默认情况下,checkpoint是关闭的。
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状 态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身 快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败 ;
Flink的容错机制 的核心部分是制作分布式数据流和操作算子状态的一致性快照。 这些快照充当一致性checkpoint,系统可以在发生故障时回滚。
- Flink分布式快照的核心概念之一是barriers。 这些barriers被注入数据流并与记录一起作为数据流的一部分向下流动。
- barriers永远不会超过记录,数据流严格有序。
Barrier对齐: 当一个opeator有多个输入流的时候,checkpoint barrier n 会进行对齐,就是已到达的会先缓存到buffer里等待其他未到达的,一旦所有流都到达,则会向下游广播,exactly-once 就是利用这一特性实现的,at least once 因为不会进行对齐,就会导致有的数据被重复处理。
反压
反压:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。
Storm 通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper ,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。
JStorm 认为直接停止 Spout 的发送太过暴力,因此通过逐级降速来进行反压的,效果会较 Storm 更为稳定,但算法也更复杂。另外 JStorm 没有引入 Zookeeper 而是通过 TopologyMaster 来协调拓扑进入反压状态,这降低了 Zookeeper 的负载。
Spark 反压 需要反压的场景:
- 首次启动Streaming应用,kafka保留了大量未消费历史消息,并且auto.offset.reset=latest,可以防止第一个batch接收大量消息、处理时间过长和内存溢出
- 防止kafka producer突然生产大量消息,一个batch接收到大量数据,导致batch之间接收到的数据倾斜
原理:
- 开启反压机制,即设置spark.streaming.backpressure.enabled 为true;
- spark会在作业执行结束后,调用RateController.onBatchCompleted() 更新batch的元数据信息:batch处理结束时间、batch处理时间、调度延迟时间、batch接收到的消息量等;
- Spark Streaming是先从broker里查询到每个分区的latestOffset,这样就可以得到每个分区的offset range,再用range和上一步预估的速率做对比计算就可以确定每个分区的处理的消息量;
- 有效速率 = min(maxRatePerPartition,预估的速率)
- 一个batch的每个分区每秒接收到的消息量 = batchDuration * 有效速率
- 若是基于Kafka Receiver的数据源,可以通过设置spark.streaming.receiver.maxRate来控制最大输入速率
- 若是基于Direct的数据源(如Kafka Direct Stream),则可以通过设置spark.streaming.kafka.maxRatePerPartition来控制最大输入速率
- 参考:https://zhuanlan.zhihu.com/p/45954932
没有使用任何复杂的机制来解决反压问题,它利用自身作为纯数据流引擎的优势来优雅地响应反压问题。
Flink 在运行时主要由 operators 和 streams 两大组件构成。分布式阻塞队列 就是这些逻辑流,队列容量是通过缓冲池(LocalBufferPool)来实现的。
Flink 中网络传输的内存管理:
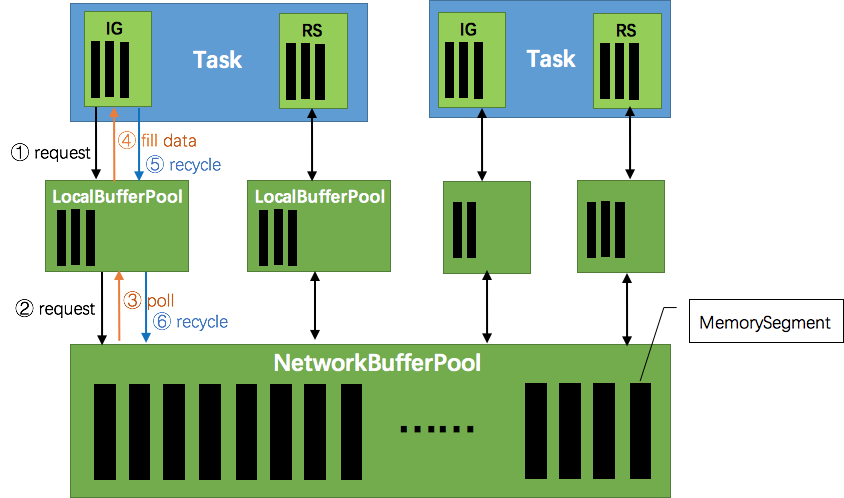
Flink 中的数据传输相当于已经提供了应对反压的机制。因此,Flink 所能获得的最大吞吐量由其 pipeline 中最慢的组件决定。
Redis
基于内存的高性能key-value数据库;采用单线程IO多路复用的设计;支持多种数据结构:String,Hash,List,Set,Zset有序集合,位图;可用作数据库、高速缓存、消息队列代理.
优势
- 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
- 支持丰富数据类型,支持string,list,set,sorted set,hash
- 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
- 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
与Memcache相比
- 存储方式,Redis可以持久化其数据;
- 支持更为丰富的数据类型;
- 使用底层模型,客户端之间通信的应用协议不一样,redis速度更快
定期删除+惰性删除策略
6种数据淘汰策略,保证redis中的数据都是热点数据
- voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据(写入报错)
RDB & AOF 持久化
- RDB(redis database):指定时间间隔对内存中的数据集快照。适合备份、容灾恢复。
- fork出子进程尽兴存储,不适合实时备份。
- 若大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB更加的高效。
- 风险是可能会丢两次持久之间的数据,量可能很大。
- AOF(append only file):持久化记录redis执行过的所有写指令,以redis协议追加保存到文件末尾。
- 可对AOP文件重写。
- AOF 的默认策略为每秒钟 fsync 一次,如果硬盘IO慢,会阻塞父进程。
- 可同时使用。如果redis重启的话,则会优先采用AOF方式来进行数据恢复,这是因为AOF方式的数据恢复完整度更高。
Redis 主从复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。一个从服务器只能有一个主服务器,并且不支持主主复制。

PS:为了保持保持数据一致性,在Master 发送完RDB文件后,还要定期的向slave发送PING命令,最后再发送变更命令。
- 在子进程保存RDB文件期间,把接受到的这些可能变更数据库“键空间”的命令保存下来,放到每个slave的回复列表中。当RDB文件发送完master会发送这些回复列表中的内容。
- 可以创建一个中间层来分担主服务器的复制工作。
Redis Hash
Redis hash 是一个string类型的field和value的映射表,适合用于存储对象(相比数据库的结构化数据,hash会占用更少的内存,稀疏)。
有两种内部编码:
-
ZipList(压缩列表) 当哈希类型的元素个数小于hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-maxziplist-value配置(默认为64字节),Redis会使用ziplist做为哈希的内部实现。Ziplist可以使用更加紧凑的结构来实现多个元素的连续存储,所以在节省内存方面更加优秀。
-
HashTable(哈希表) 当哈希类型无法满足ziplist要求时,redis会采用hashtable做为哈希的内部实现,因为此时ziplist的读写效率会下降。
rehash
redis支持多种数据结构,其中dict是使用频率相当高。
- 内部采用拉链法解决哈希冲突
- 扩容采用渐进式 rehash
- dict的内部,维护了两张哈希表;
- 在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行;
- 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作;
- 将 rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
缓存穿透,击穿,雪崩
缓存穿透:是指查询一个一定不存在的数据,因为缓存中也无该数据的信息,则会直接去数据库层进行查询,从系统层面来看像是穿透了缓存层直接达到db,从而称为缓存穿透。
解决:
- 缓存空值
- BloomFilter 类似于一个hbase set 用来判断某个元素(key)是否存在于某个集合中。
缓存击穿:在平常高并发的系统中,大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。
解决:
- 本质是多个线程同时去查询数据库的这条数据,可以在第一个查询数据的请求上使用一个互斥锁来锁住它。
- 二级缓存:对于热点数据进行二级缓存,并对于不同级别的缓存设定不同的失效时间,则请求不会直接击穿缓存层到达数据库。
- 结合LRU算法
缓存雪崩:当某一时刻发生大规模的缓存失效的情况,比如你的缓存服务宕机了,会有大量的请求进来直接打到DB上面。结果就是DB 称不住,挂掉。
解决:
- 事前:使用集群缓存,保证缓存服务的高可用,比如Redis 主从+哨兵。
- 事中:ehcache本地缓存 + Hystrix限流&降级,避免MySQL被打死。
- 事后:开启Redis持久化机制,尽快恢复缓存集群。
解决热点数据集中失效问题:
- 设置不同的失效时间
- 互斥锁(会阻塞其他的线程,此时系统吞吐量会下降)
hot key & big key
- hot key出现造成集群访问量倾斜:
- 使用本地缓存
- 利用分片算法的特性,对key进行打散处理
- big key 造成集群数据量倾斜:
- 对 big key 进行拆分
数据一致性
数据库和缓存之间一般不需要强一致性:
- 读的顺序是先读缓存,后读数据库。读Redis 涉及全量 / 增量同步Mysql 数据。
- 写的顺序是先写数据库,然后写缓存。
- 每次更新了相关的数据,都要把该缓存清理掉。
- 为了避免极端条件下造成的缓存与数据库之间的数据不一致,缓存需要设置一个失效时间。时间到了,缓存自动被清理,达到缓存和数据库数据的“最终一致性”。
-
第一种方案:采用延时双删策略
-
第二种方案:异步更新缓存(基于订阅binlog的同步机制)
- binlog增量订阅消费+消息队列+处理并把数据更新到redis
分布式锁
分布式锁通常实现:
- 基于 DB 的唯一索引。
- 基于 ZK 的临时有序节点。
- 基于 Redis 的 NX EX 参数
Redis为单进程单线程模式,Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争。
INCR
- 如果key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作进行加1。
- 然后其它用户在执行 INCR 操作进行加一时,如果返回的数大于 1,说明这个锁正在被使用当中。
SETNX
- 如果 key 不存在,将 key 设置为 value
- 如果 key 已存在,则 SETNX 不做任何动作
SET 利用:Redis set key 时的一个 NX 参数可以保证在这个 key 不存在的情况下写入成功。并且再加上 EX 参数可以让该 key 在超时之后自动删除。
1、 客户端A请求服务器设置key的值,如果设置成功就表示加锁成功
2、 客户端B也去请求服务器设置key的值,如果返回失败,那么就代表加锁失败
3、 客户端A执行代码完成,删除锁
4、 客户端B在等待一段时间后在去请求设置key的值,设置成功
5、 客户端B执行代码完成,删除锁
常见性能优化
- Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
- 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
- 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
- 尽量避免在压力很大的主库上增加从库
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
Kafka
Exactly Once
Kafka 提供三种语义的传递:
- 至少一次 (at least once) 消息不会丢失 ack=all ,但是可能重复投递
- 至多一次 (at most once) 消息可能丢失,但是不会重复投递
- 精确一次 (Exactly Once) 消息不会丢失,也不会重复
消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过producer.type属性进行配置。
Kafka通过配置request.required.acks属性来确认消息的生产:
0---表示不进行消息接收是否成功的确认;
1---表示当Leader接收成功时确认;
-1---表示Leader和Follower都接收成功时确认;
解决:
- 同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;
- 异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
消息消费
- Low-level API:消费者自己维护offset等值,可以实现对Kafka的完全控制;
- High-level API:封装了对parition和offset的管理,使用简单;
解决:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
高吞吐量
顺序读写
顺序追加到文件尾。 Memory Mapped Files:利用操作系统的Page实现文件到物理内存的映射,提高了IO速率,不用在用户空间到内存空间的复制。(缺点:不可靠)
Zero Copy
正常模式,经历4次copy的过程:
- 调用read时,文件A拷贝到了kernel模式;
- CPU控制将kernel模式数据copy到user模式下;
- 调用write时,先将user模式下的内容copy到kernel模式下的socket的buffer中;
- 将kernel模式下的socket buffer的数据copy到网卡设备中传送;
Linux内核sendfile系统调用,提供了零拷贝。Zero-Copy来请求kernel直接把disk的data传输给socket, Linux2.4内核对sendfile改进版:
- 将文件拷贝到kernel buffer中;
- 向socket buffer中追加当前要发生的数据在kernel buffer中的位置和偏移量;
- 根据socket buffer中的位置和偏移量直接将kernel buffer的数据copy到网卡设备(protocol engine)中.
Replication
Kafka的消息安全性与容灾机制主要是通过副本replication的设置和leader/follower的的机制实现的。
Kafka 每个partition都有一个唯一的leader,所有的读写操作都在leader上完成,leader批量从leader上pull数据。一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。follower上的日志和其leader上的完全一样。
Kakfa处理失败需要明确定义一个broker是否alive。对于Kafka而言,Kafka存活包含两个条件:
- 它必须维护与Zookeeper的session(这个通过Zookeeper的heartbeat机制来实现)
- follower必须能够及时将leader的writing复制过来,不能“落后太多”
leader会track “in sync”的node list(ISR)。如果一个follower宕机,或者落后太多,leader将把它从”in sync” list中移除。
对于Consumer而言: list里的所有follower都从leader复制过去才会被认为已提交。这样就避免了部分数据被写进了leader,还没来得及被任何follower复制就宕机了,而造成数据丢失(consumer无法消费这些数据)。
而对于producer而言: 它可以选择是否等待消息commit,这可以通过request.required.acks来设置。这种机制确保了只要“in sync” list有一个或以上的flollower,一条被commit的消息就不会丢失。
leader 选举机制 Kafka在Zookeeper中动态维护了一个ISR(in-sync replicas) set,这个set里的所有replica都跟上了leader,只有ISR里的成员才有被选为leader的可能。
Zookeeper保证一致性 Zab 协议类似于 Paxos 协议,并且提供了强一致性。
副本同步机制
多机房数据一致性问题:(跨城市容灾)
MirrorMaker 工具:Kafka 官方提供的跨数据中心的流数据同步方案。其实现原理,其实就是通过从Source Cluster消费消息然后将消息生产到Target Cluster,即普通的消息生产和消费。用户只要通过简单的consumer配置和producer配置,然后启动Mirror,就可以实现准实时的数据同步。
消息中间件
容灾
分布式锁
分布式锁的几种使用方式(redis、zookeeper、数据库)
海量数据
海量数据处理 基本都是分治的思想。
